Background >
Hyperparameter Optimization
Many of the machine learning models have hyperparameters, i.e., configurations of the model that we decide before training a model. For example, the number of mixer layers in a TS Mixer, the number of trees in a random forest, or the number of neurons in each layer of a neural networks.
Grid Search
Grid search lists all the combinations of the paramters and train model for each to find the best. Take LSTM as example. It has paramters to set such as the number of hidden states and the number of layers. Let's say we have the following paramters to try.
- The number of hidden states: 2, 3, 5, 10
- The number of layers: 1, 2, 3
Grid Search in Time Series Cross Validation
Unlike tabular data, when using Time series cross validation, each split naturally has different sizes. For example, the first split's training data size might be 200 while the last one is 2,000. This makes using the same parameters across splits nonsensical. For example, the number of leaves in a GBM should ideally be different for each split.
To address this, we try different values across the split sizes. For instance, 200 rows of data might be tested with 10 and 20 leaves, while 2,000 rows of data might be tested with 50, 100, and 200 leaves. These treatments can be defined as either a function or as predefined numbers that apply to varying split sizes.
Bayesian optimization
Instead of blindly testing all combinations, we can use advanced algorithms like Bayesian optimization. The idea is that as we observe more of model performances, we become more confident about the performance around those observations. Using a method like Gaussian Process, we can make a prediction of the model performance at different parameter values. Confidence around the known data points will be narrow while it would be wider at unexplored areas.
For example, let's say model performance was 20, 32, and 5 when we set a model paramter to 2, 3, and 5. We then have (paramter, performance) pairs of (2, 20), (3, 32), and (5, 5) in our knowledge. Gaussian Process then tell us predicted model performances, expressed as confidence intervals, at different parameter values.
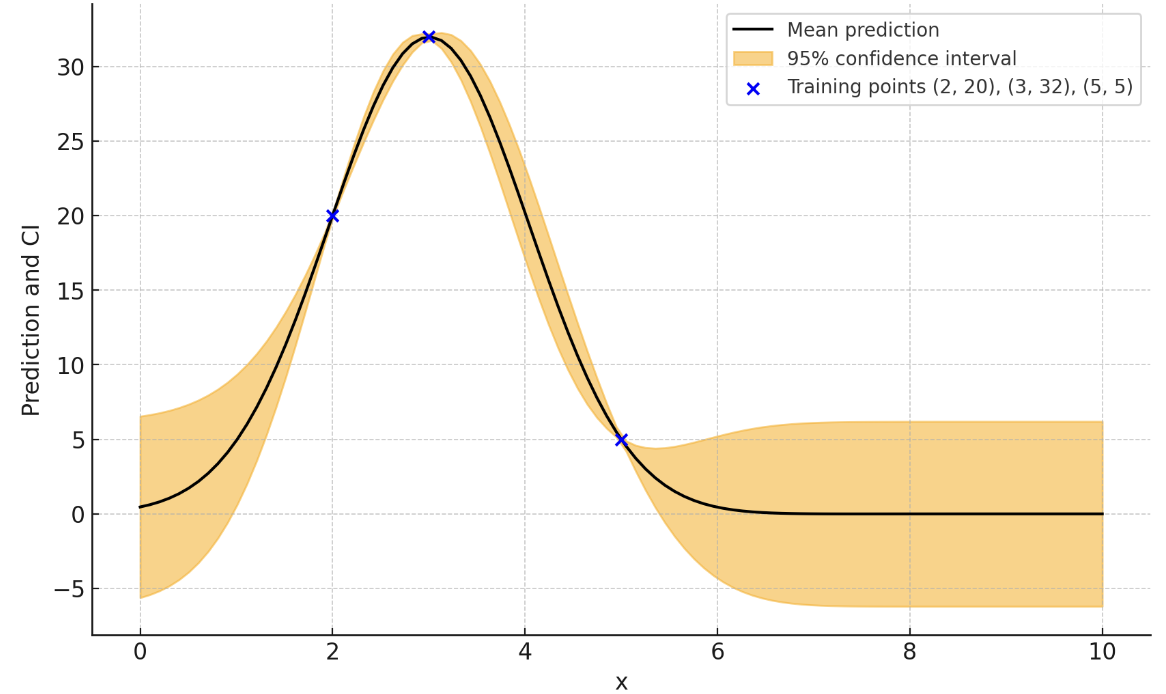
Example of Bayesian Optimization after finding model performances at 2, 3, and 5.
Based on such knowledge, at each step towards finding the best parameters, we can choose between exploit (trying the most promising parameter) or explore (trying new parameters). Balancing the two, bayesian optimization is able to find the best parameters efficiently within the limited number of experiments.
Gaussian Process isn't the only algorithm, by the way. There are others such as TPE (Tree-structured Parzen Estimator). But the basic concept still applies.